Secure by Default: An Architecture for Governing AI Coding Agents
A control plane for AI coding agents. Why governing agents through prose in CLAUDE.md does not scale, and what a hooks-based enforcement layer with default-deny egress and signed, version-controlled policy looks like in practice.
AI coding agents now write code, run shell commands, call external tools, open pull requests, and touch infrastructure. The instruction that used to live in a prompt has turned into an actor with hands. Most teams still govern that actor the way they governed a chatbot: by writing rules in a Markdown file and hoping the model follows them.
That works until it doesn’t. A line in CLAUDE.md saying “never read .env” is guidance, and a capable model will usually honor it. But guidance is not a boundary. The model decides whether to follow the sentence; nothing physically stops it. In a single hobby repo that gap is tolerable. Across a regulated engineering environment with many repositories and several different agents, prompt discipline does not scale and prose is not a control.
I built a secure-by-default control plane for AI coding agents to close that gap, and I have been running it since April 2026 across a real, regulated, multi-repo environment. This is the architecture I settled on and why I think the pattern matters in 2026.
Enforcement belongs in the runtime, not in the prose
The organizing principle is simple: behavior is guidance, enforcement is mechanism. Anything that matters for security or compliance must be enforced by something the model cannot talk its way past, managed settings, lifecycle hooks, tool allowlists, and CI gates, not by a paragraph it is asked to respect.
This reframes the agent’s configuration as a trust boundary rather than documentation. The files that tell an agent which tools it may call, where it may deploy, and how it handles secrets are now part of the execution path. They deserve the same treatment as Terraform, Kubernetes manifests, or GitHub Actions: version control, review, and runtime enforcement, not freeform text edited at will.
A useful way to hold the split is that the model decides what to do and the runtime decides whether it is allowed. The model proposes; the control plane disposes.
The architecture
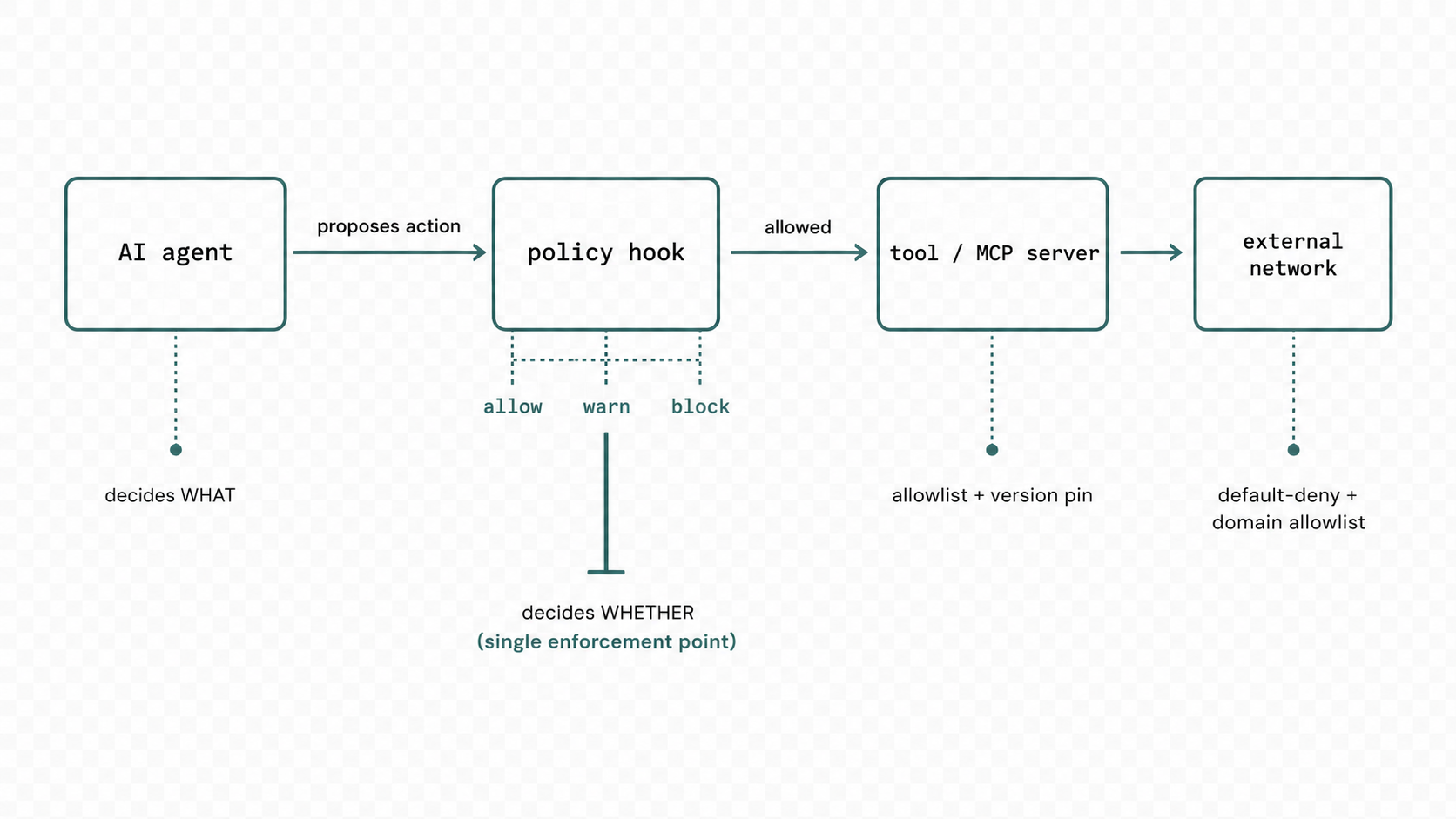
The control plane sits between the agent and everything it can touch. The agent proposes an action; a hook decides whether the action is allowed; only then does it reach a tool, an MCP server, or the network.
agent ──proposes──▶ hook (decides whether) ──allowed──▶ tool / MCP ──▶ external egress
│ ▲ ▲
allow │ warn │ block allowlist + default-deny +
version pin domain allowlistFive design choices carry most of the weight.
One source of truth, generated adapters. Policy is written once in a canonical, vendor-neutral form, and the per-agent files (the Claude, Cursor, and Copilot variants) are generated from it rather than hand-maintained in parallel. AGENTS.md, which became a Linux Foundation project under the Agentic AI Foundation in December 2025, is the natural anchor. Writing policy five times for five agents guarantees drift; generating it from one source removes a class of inconsistency that an attacker, or a tired engineer, would otherwise exploit.
Hooks as the enforcement plane. A hook fires at a defined point in the agent’s lifecycle, reads the action the model wants to take, and returns a decision. The high-impact decisions are made here, in code, not in the model’s good intentions. A pre-action hook, simplified:
on PreToolUse(event): # fires BEFORE the action runs
a = parse(event) # tool, args, target path, destination
if policy_failed_to_load(): # fail closed for the dangerous set,
return BLOCK if high_risk(a) # not for everything: a broken cache
else WARN # must not halt ordinary work
if reads_secret(a) # .env, ~/.aws, ~/.ssh, /proc/self/environ
or edits_control_plane(a) # CI config, agent config, tool manifest
or publishes_or_deploys(a)
or egress_to_unlisted_host(a):
return BLOCK unless single_use_human_approval(a)
return ALLOW # everything else proceeds, and is loggedTwo details matter more than they look. The hook must fail closed for the dangerous set: if it cannot evaluate the policy, it denies rather than waving the action through, because a hook that silently disables when its environment breaks is worse than no hook at all. And it must run before the action, not after, a scanner that inspects a tool result once the call has already returned is a useful layer, but by then the content is in the model’s context.
Hard-block the dangerous few, warn on the rest. The split is what keeps approvals meaningful. On a payment service, the operations that must never happen silently are the convergence of secrets, untrusted input, and an external destination: reading a credentials file and reaching an unlisted host in the same step, editing a CI workflow, or running a publish. Those hard-block and require a single-use human approval. Ordinary in-repo edits warn and log. If every action needs a click, people stop reading the clicks. Anthropic’s own data has users accepting roughly 93% of permission prompts, so a gate works only when it is rare.
Default-deny egress as the backstop. Allowlisting tools is necessary but not sufficient, because tools have bugs and injections get through. The control that actually contains a missed injection is least privilege plus default-deny network egress: a successful prompt injection has nowhere to send the data if the agent can reach only an allowlisted set of hosts. This is also the honest limit of the pattern. An agent talking to a local tool over stdio can move data in ways a network hook never sees, which is why tool allowlisting and version pinning sit alongside egress control rather than replacing it.
Auditability as a byproduct. In this pattern, every consequential decision is appended to a tamper-evident log, and the artifacts the agent relies on are signed. The record is small and boring on purpose:
{ ts, agent_id, action, target, decision, policy_id, approval_id? }For a regulated backend, that log is the audit trail a regulator asks for, produced by normal operation rather than reconstructed under deadline. When “what did the agent do, and was it allowed to” has a durable answer by default, compliance stops being a quarterly scramble.
None of this is exotic. It is ordinary platform-security thinking, least privilege, signed artifacts, immutable logs, supply-chain hygiene, applied to a new kind of actor.
The industry is converging on the same shape
I did not arrive at this in isolation. Over the same period, the major platforms have converged on a similar architecture.
Microsoft’s open-source agent-governance-toolkit lands on the same primitives I did: a deterministic policy kernel that fails closed, workload identity, and tamper-evident audit, integrating with common agent frameworks. GitHub made its Enterprise AI Controls and Agent Control Plane generally available in early 2026, with model-restriction policies and audit-log streaming, and its guidance strongly encourages running agents with those controls enabled. Anthropic’s engineering writing on containing Claude is explicit that security belongs in sandboxing, egress control, and enforcement rather than in the wording of a context file. And the AGENTS.md format moving under neutral Linux Foundation governance signals that the configuration layer is becoming shared infrastructure with its own standards.
The same design arriving independently, in my own work and in the major platforms, is a reasonable signal that the shape is right. Prose-to-runtime enforcement and treating configuration as a trust boundary are common patterns in 2026, not edge cases.
Why this matters now
Two forces moved this from good practice to baseline expectation.
The first is the MCP supply-chain incident wave. Over the first half of 2026, researchers disclosed a series of remote-code-execution flaws across the tool ecosystem: OX Security’s “Mother of All AI Supply Chains” report described a systemic STDIO flaw in affected packages with more than 150 million combined downloads, and named vulnerabilities like the unauthenticated RCE chain in the widely used Atlassian MCP server (CVE-2026-27825) and the one-click RCE in Flowise (CVE-2026-40933) showed that a poisoned tool or a malicious configuration import can execute arbitrary code on a developer’s machine. The tool and configuration layers are now an attack surface in their own right, and a written policy does not stop a poisoned tool result from running a shell command.
The second is regulation catching up. The EU AI Act’s provisions on automatic event logging over a system’s lifecycle and on human oversight, the ability to understand, intervene, and halt, map almost directly onto an architecture that already produces an immutable decision log and gates high-impact actions behind a human. Building the control plane this way means the compliance evidence largely exists as a side effect of how the system runs.
Put together, secure-by-default agent governance is moving from nice-to-have to baseline. If your agents have hands, the question is no longer whether to govern them, but whether your governance is a paragraph or a mechanism.
What’s next
This piece is the overview. In the next articles I will go a layer deeper into the parts that matter most in practice, hardening the tool supply chain, and treating the agent’s policy layer as production attack surface with the same versioning, signing, and review you give to code.
Further reading: Anthropic, “How we contain Claude across products”. EU AI Act, Article 12 (record-keeping).